Z biegiem postępu prac poniższy wpis będzie aktualizowany.
Lab w oparciu o pomysł, który opisałem we wpisie: Pomysły projektów dla Młodszego Administratora Linux (Junior Linux System Administrator)
Na niewykorzystywanej jednostce centralnej zainstalowałem Proxmox’a (który zresztą tu był poprzednio, ale chciałem czystą instalację). Aby zarządzanie serwerem było dostępne z dowolnego miejsca podpiąłem go pod jFroga. Dlaczego nie CloudFlare albo inne tego typu rozwiązania? Między innymi ze względów bezpieczeństwa – serwer dostępny jest jedynie po ustanowieniu tunelu przez froga. Tutaj też małe wtrącenie, jFrog w pakiecie podstawowym obsługuje 3 urządzenia. Warto było zajrzeć do powiadomień, aby dowiedzieć się, że brak zainstalowanego przed chwilą serwera nie oznacza błędu podczas instalacji/konfiguracji, ale po prostu limit urządzeń na koncie 😀
Dodatkowo w BIOSie ustawiłem opcję, aby PC sam się włączał po powrocie zasilania (kończę pracę i wyłączam, później przycisk na zasilaczu wędruje na 0, następnie wystarczy jedynie przełączyć zasilacz na 1 i sam się uruchamia – spróbujcie komuś przetłumaczyć jak się odpala PC na krótko 😀 Obecnie nie ma przedniego panelu w obudowie, więc są podłączone gołe kable, które po zwarciu załączają).
Schemat laba:
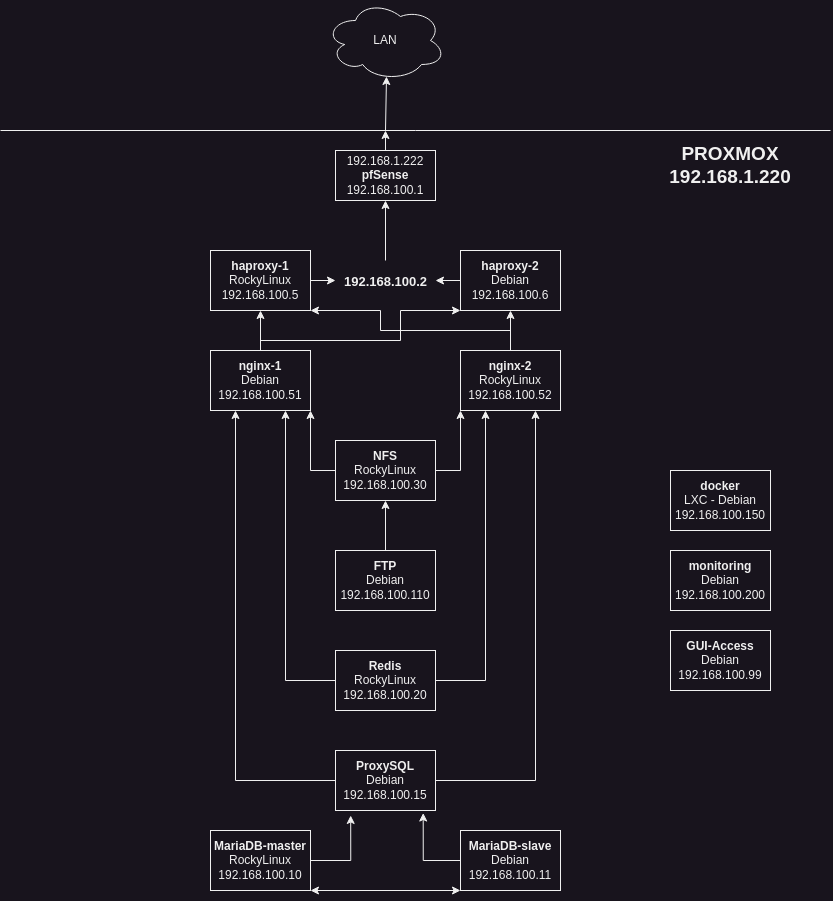
Po skonfigurowaniu powyższego przyszedł czas na utworzenie VM. Plan był prosty: przygotować Debian i RockyLinux jako szablony. No i problem – KernelPanic podczas próby uruchomienia RockyLinux. Po diagnostyce okazało się, że problemem jest CPU. Konieczne było zainstalowanie Rockiego w wersji 8.
Do tej pory na VirtualBoxie używam Ubuntu, no bo przygotowywałem dla techników, został, niech już będzie. Tutaj w rozpędzie też otworzyłem stronę Ubuntu Server, ale zapaliła się lampka w głowie 😀 Szybki ruch myszką w kierunku wyszukiwarki -> „debian download” 😀
Co zawiera szablon? Zaktualizowany na dzień dzisiejszy system + utworzone odpowiednie konta + odpowiednio skonfigurowane SSH + zainstalowany ZSH (którego jestem fanem 😉 )
Gdy szablony były gotowe utworzyłem VM z pfSensem, który będzie pełnił rolę bramy domyślnej dla całej podsieci labowej. Dodatkowo utworzyłem nową sieć Linux Bridge (192.168.100.0/24), która będzie wewnętrzną, do której będą wpięte wszystkie wirtualki i interfejs LAN pfSensa. Konfiguracja peefa ograniczyła się do przypisania statycznych adresów IP na interfejsach 🙂
Projekt rozpocząłem od instalacji serwerów bazodanowych. Dlaczego akurat od nich? Chciałem przećwiczyć replikację, którą miałem z tyłu głowy. Wiedziałem, że istnieje, ale nie labowałem jeszcze jej do tej pory. Klonowanie obu templatek (Rocky jako master, Debian jako slave). Instalacja mariadb, a następnie mysql_secure_installation. Gdy miałem już działające serwery przystąpiłem do konfiguracji replikacji. Wykorzystałem do tego dokumentację na mariadb.com.
Swoją drogą coraz bardziej zaczynam przekonywać się do manuali dostawcy / producenta w miejsce przypadkowych tutoriali znalezionych w necie. Tak, tak, wiem. Ale na początku przygody z administracją dużo lepiej czyta się proste tutoriale, a nie skomplikowane, techniczne dokumentacje. Niech pierwszy rzuci kamieniem ten, który zamiast klepnąć problem w Goole czyta manuale 😀.
Dodatkowo konieczne było odblokowanie portu na firewallu w przypadku Rockiego. Po konfiguracji całości szybki test na masterze: utworzenie bazy, utworzenie użytkownika, nadanie uprawnień użytkownikowi do nowej bazy. Sprawdzenie na slave – jest, czyli działa. Sprzątanie (bo po co mi jakieś dane testowe, bezpieczeństwo przede wszystkim ;)) w odwrotnej kolejności – drop user i database na slave. Zgadza się – czyściutko 😀
Następnym krokiem była instalacja serwera NFS. Akurat jego przerabialiśmy na studiach, w związku z tym z grubsza ogarniam ten temat. Do VM dodałem dwa dyski, które spiąłem RAID’em 1 (mirroring). Zależy mi na bezpieczeństwie danych, dlatego akurat taki wybór. Po podmontowaniu go do systemu, udostępniłem mountpoint dla trzech hostów: serwer FTP oraz dwa nginxy.
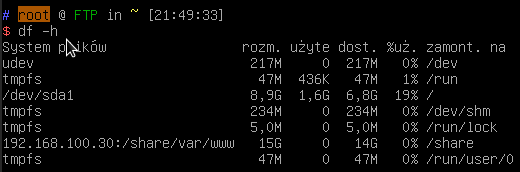
Gdy wszystko było skonfigurowane utworzyłem VM z przeznaczeniem na serwer FTP. Podmontowałem jedynie utworzony udział, w celu przetestowania NFSa. Wszystko działa, więc ten serwer na chwile zostaje „zawieszony”.
Następnym etapem będą serwery NGINX. Akurat jak je ugryźć sprawia mi najwięcej „problemów”. W przypadku serwerów bazodanowych stwierdziłem, że master podpinam pod WWW, slave jest jako zapasowy. Mógłbym dodać jakieś proxy, ale bez różnicy czy padnie proxy czy padnie master – efekt taki sam, a tylko 1 punkt, który może położyć całe DB. Może ugram tym samym trochę na wydajności 🙂 Wracając do nginx, chciałbym aby oba były bliźniacze, tj. serwowały takie same strony (WordPressy). Kwestia DB załatwiona, pliki w sumie też na jednym serwerze NFS. Awaryjność załatwi HAProxy. Zastanawiałem się, aby postawić je na Dockerze, ale na razie chcę spróbować na pełnych systemach. W związku z tym przystępuje do testów: instaluje na obu nginx, montuje udziały do domyślnych DocumentRoot’ow na serwerach przez nfs. Na Debianie ruszyło od strzała, na Rockim był pewien problem – błąd 403. SELinux się aktywował 😉 Następnie przepiąłem Rockiego również na katalog /var/www/html, gdyż będzie jeden plik z vhostami serwowany na oba serwery.
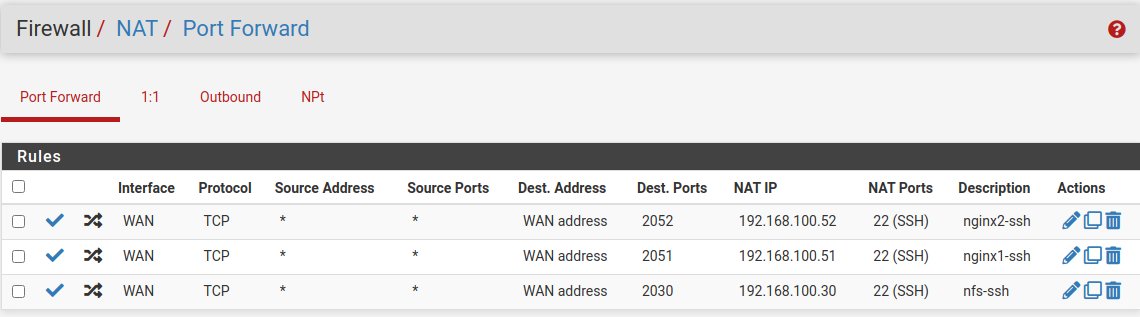
Na pfSense dodałem przekierowania portów umożliwiając dostęp do serwerów przez SSH z zewnątrz. Celem był dostęp z sieci domowej do wszystkich serwerów wewnątrz sieci Proxmoxowej. Porty dodawałem wg schematu 2000+adres_IP_serwera -> 22.
Gdy powyższe miałem gotowe przystąpiłem do instalacji PHP-FPM na WEB serwerach. Wykorzystałem wersję 7.4 oraz 8.1. Na Debianie udało się od strzała. Na Rockim pojawiło się trochę schodów, ale po dodaniu remi-php-repo udało się zainstalować (za drugim podejściem). Pierwsze zakończyło się przywróceniem snapshota, w drugim trzeba było się trochę pobawić konfiguracją obu php-fpm, aby lokalizacje socketów były takie same na obu systemach (co w domyślnej konfiguracji jest rozbieżne) + zmiana właściciela tych socketów na nginx. Finalnie wyrzeźbiłem jeszcze skrypt bashowy, który tworzy odpowiedni katalog, restartuje usługi fpm (aby utworzyły sockety w tym katalogu) oraz zmienia właściciela socketów. Z jego wykorzystaniem utworzyłem usługę, która startuje wraz ze startem systemu.
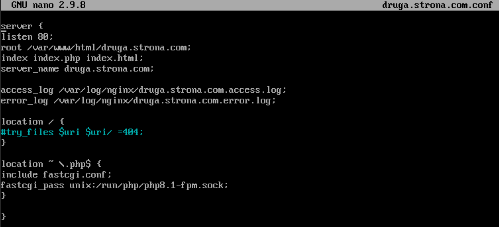
Dodatkowo utworzyłem dwa pliki konfiguracyjne dla wirtualnych hostów na udziale vhost na serwerze NFS i podmontowałem go odpowiednio do katalogu conf.d (Rocki) oraz sites-enabled (Debian).
![]()
Ten udział został udostępniony w trybie RO, ponieważ serwer nie musi nic zapisywać w tych plikach konfiguracyjnych. Wykorzystałem domeny:
– wojst.pl.lcl (php7.4)
– druga.strona.com (php8.1)
Na pierwszej będzie odtworzona moja strona firmowa wojst.pl z ostatniej kopii zapasowej, druga natomiast będzie zawierała testowego WordPressa. Na udziale WWW utworzyłem dwa podkatalogi dla poszczególnych stron i wrzuciłem do nich index.html wyświetlający domenę – posłużył do przetestowania czy na obu serwerach działają oba vhosty.
Czas powrócić do serwera FTP. Zainstalowałem proftpd, wyłączyłem dostęp dla anonymous. Dodałem użytkowników lokalnych (jako homedir katalog z udziału podmontowanego z NFSa, shell false). Skonfigurowałem, aby serwer działał tylko jako SFTP. Zmodyfikowałem konfigurację, aby wpuszczała jedynie userów z grupy ftp_users (do której dodałem obu użytkowników). Pierwotnie pojawił się problem, ponieważ nie miałem modułów odpowiedzialnych za sftp. Jak się okazało zainstalowała się wersja proftpd-core, która ich nie posiada. Konieczne było zainstalowanie wersji basic tego pakietu.
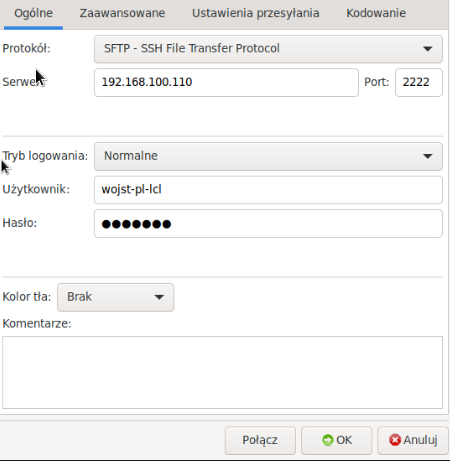
Podczas uploadu plików okazało się, że pliki jako właściciela mają user:grupa z serwera FTP. Spowodowało to problemy na serwerach WWW (user i gid ustawione na 1002). Konieczna była rekonfiguracja serwera FTP, aby ustawiał właściciela jako nginx. Niestety SetOwner, UserOwner itp. nie chciało działać. Wykonywanie skryptu podczas uploadu też niekoniecznie, ponieważ DocumentRoot miałem ustawiony na ~. ChatGPT (po dłuższym czasie, bo też musiałem się z nim trochę pokopać „Przepraszam, wprowadziłem Cię w błąd„) podpowiedział, aby stworzyć skrypt Pythonowy, który nasłuchuje w danych katalogach i jak coś do niego wpadnie wówczas robi chowna. Odpaliłem ten skrypt jako usługę. Działa.

Proxmox na ten moment wygląda następująco: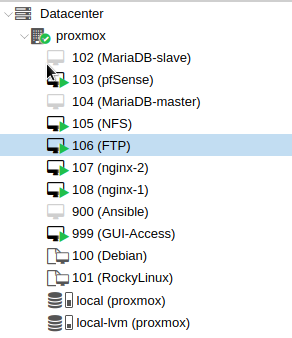
Serwery bazodanowe chwilowo wyłączone, ponieważ jednak spróbuję wdrożyć ProxySQL.
Odpalone maszyny na ten moment są skończone (skonfigurowane). GUI-Access jest to Debian z zainstalowanym LXDE, który wykorzystuje do testów (poprawność działania vhostów nginx), wrzucenie plików na FTP przez filezille itd itp.
W kolejnym etapie przyszedł czas na ProxySQL. Na podstawie oficjalnej dokumentacji (i kilku tutoriali z YT) zainstalowałem go na VM pod kontrolą Debiana. Konfigurację rozszerzyłem o zmianę domyślnego hasła admina. Replikację MariaDB miałem już włączoną wcześniej. Serwer master jest w grupie „WRITE„, natomiast slave w grupie „READ„. Zapytania SELECT wędrują na serwer master, natomiast pozostałe na serwer slave.

Gdy to miałem gotowe przez FTP wrzuciłem pliki kopii zapasowej strony wojst.pl, a na serwerze master utworzyłem odpowiedniego użytkownika i z wykorzystaniem mysqldump zaimportowałem backup bazy danych. Zmodyfikowałem również plik wp-config.php podając jako serwer baz danych adres IP ProxySQLa. Pierwsza próba uzyskania dostępu do strony zakończona błędem:
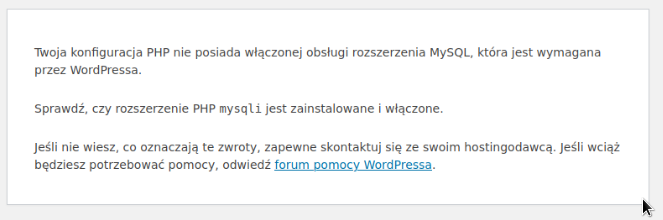
Zainstalowałem php7.4-mysql (php74-php-mysqlnd) oraz php8.1-mysql (php81-php-mysqlnd) ona obu web serwerach. Po drobnych modyfikacjach plików konfiguracyjnych WP strona ruszyła 🙂
Do tego momentu musiałem przełączać wpisy w /etc/hosts jeżeli chodzi o adresy IP dla stron testowych. Przyszedł czas na wdrożenie HAProxy. Pierwotnie myślałem o jednej maszynie, jednak w trakcie czytania na ten temat rzuciła mi się w oczy opcja keepalived. Jest ona odpowiedzialna za przełączanie load balancerów. Eliminujemy tym samym jeden punkt błędu, tj. jeżeli padnie loadbalancer nie położy nam to całej infrastruktury.
Utworzyłem dwie maszyny, klasycznie jedna na Debianie druga na Rockim. Zainstalowałem HAProxy oraz Keepalived. No i? Nie działa… Czas na troubleshooting. Wyłączyłem keepa, zabawa z logami itd itp. Jak się okazało zrobiłem czeski błąd w konfiguracji HAProxy – wpisałem adresy IP maszyn z HA zamiast z nginxem. Po podmianie i uruchomieniu obu usług wszystko działa. Ładuje przemiennie strony z serwera nginx-1 i nginx-2.
Proxmox w tym momencie prezentuje się następująco: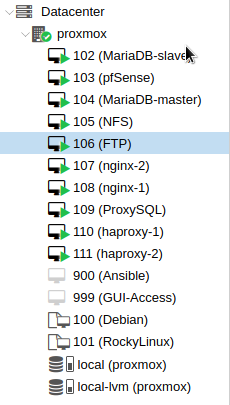
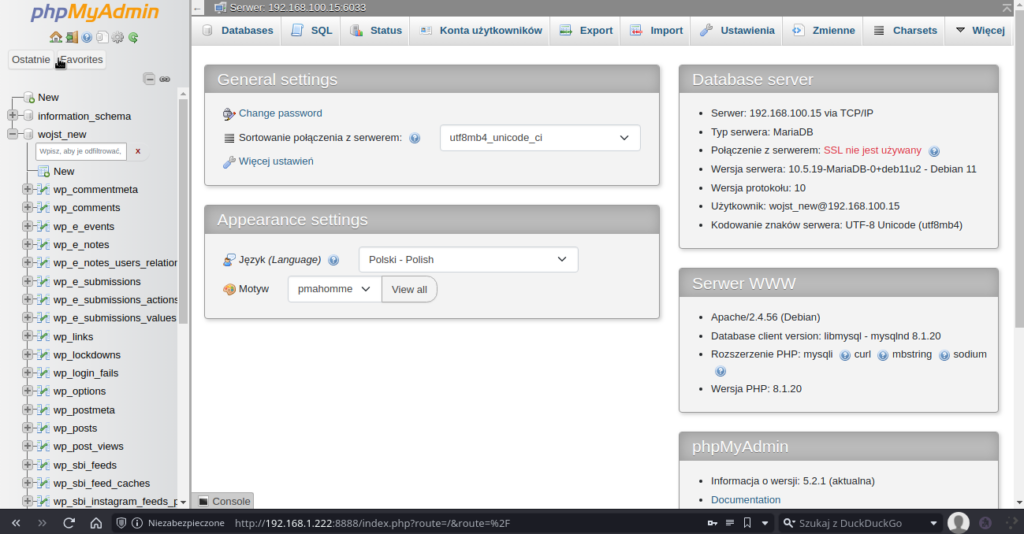
W Proxmoxie utworzyłem CT z Debianem 11, na którym zainstalowałem Dockera. Następnie utworzyłem kontener z phpMyAdmin, który łączy się do ProxySQL na porcie 6033:
docker run -d –name phpmyadmin -e PMA_HOST=192.168.100. -e PMA_PORT=6033 -p 8080:80 phpmyadmin
Próba zalogowania na użytkownika wojst_new zakończona powodzeniem:
Docelowo chciałem podpiąć URL domena/phpmyadmin aby proxowało ruch do kontenera, ale najpierw z sieci domowej (zewnętrznej dla Proxmoxa) przetestowałem działanie domen. Przekierowanie portu 80 na pfSense kieruje już na adres HAProxy, domeny dodane do /etc/hosts na laptopie. No i problem… Wyświetla się domyślny plik index.html. Szybka diagnostyka curlem na web serwerach – zwraca domyślny index. Diagnostyka z lsofem, no faktycznie nie ma otwartych plików z vhostami. Jak się okazało jeden serwer działał prawidłowo (obsługiwał obie strony), natomiast na drugim, tym z RockyLinux, był błąd na obu. Problemem były pliki konfiguracyjne vhostów.
Gdy strony ruszyły na obu serwerach, HAProxy rozrzucał ruch na obu powróciłem do tematu przekierowanie /phpmyadmin na kontener. Można to rozwiązać z wykorzystaniem snippetów, jednakże trzeba to robić oddzielnie na wszystkich web serwerach. Najszybszym rozwiązaniem dla mojej topologii (tak mi się wydaje w tym momencie) będzie dorzucenie dyrektywy w plikach konfiguracyjnych na serwerze NFS.
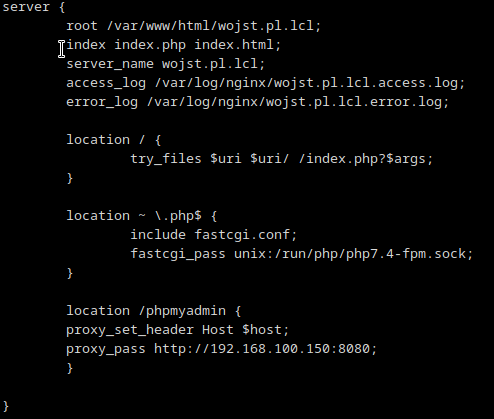
Przeładowanie nginxów i test zakończony błędem – The requested URL was not found on this server. No ok, to jako świeży maniak strace podpinam się pod workera nginxa i debugging – co tam się dzieje po kolei? Socket ładnie podpina i na tym koniec, bo docker wywala błąd, że nie może znaleźć /phpmyadmin. Swoją drogą na stronie jak wół wywala błąd Apache (Debian), a przecież na web serwerach mam nginxa -_- Zmodyfikowałem dyrektywę i teraz biały ekran. Czyli mamy postęp 😀 Tym razem przepięcie strace na Dockera, bo to on teraz generuje problemy. W międzyczasie szybka konsultacja z wujkiem DuckDuckGo. Trzeba było zmodyfikować dyrektywę z vhoście i zmodyfikować zmienne środowiskowe w kontenerze.
Konfiguracja vhosta:
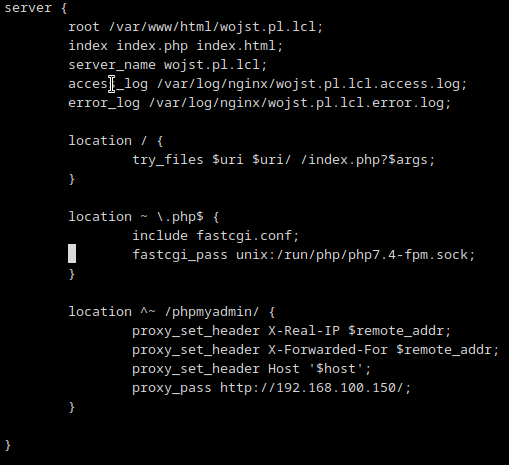
I uruchamianie kontenera:
![]()
Zalogowanie zakończone powodzeniem:
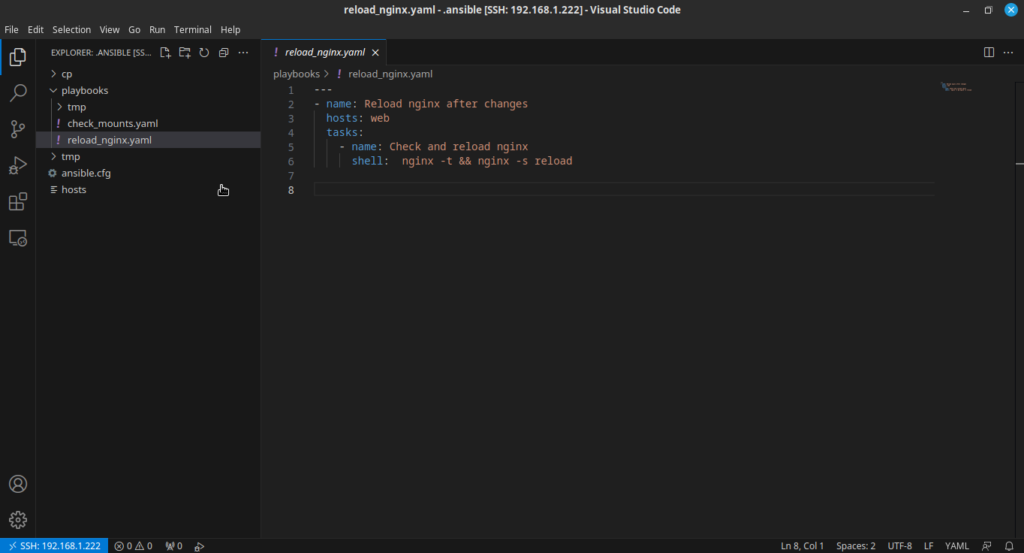
Podczas powyższej diagnostyki często musiałem robić reload nginxa na obu serwerach. Brakowało mi Ansible w tym momencie. Uruchomiłem VM z Debianem, która będzie służyła jako kontroler Ansible. Na laptopie zainstalowałem VSCode oraz rozszerzenie Ansible, a następnie podpiąłem się do zdalnego hosta poprzez SSH. Dzięki temu w prostszy sposób mogę tworzyć playbooki.
Podczas przeglądania YT wpadł mi w oko film odnośnie web UI do Ansible. Pozwala ono na podpięcie zdalnego repo z playbookami. W znacznym stopniu ułatwiłoby to zdalne zarządzanie labem – piszę sobie playbooka w VS Codzie na laptopie, commituje do repo i później tylko uruchamiam taska przez web UI. Szybki przegląd dokumentacji Semaphore (bo o nim mowa) i utworzenie usera oraz bazy danych na MariaDB-master. Należy wspomnieć w tym miejscu, że należy nadać uprawnienia dla user@IP_proxysql do tworzonej bazy. Następnie na hoście z Dockerem uruchomiłem za pomocą docker-compose instancję semaphore. Jako repo wykorzystałem to od challengu #100DaysOfLinux .
docker-compose.yaml :
version: '3.4′
services:
semaphore:
restart: always
ports:
– 3000:3000
image: semaphoreui/semaphore:latest
environment:
SEMAPHORE_DB_USER: ansible_ui
SEMAPHORE_DB_PASS: /run/secrets/mysql_password
SEMAPHORE_DB_HOST: 192.168.100.15
SEMAPHORE_DB_PORT: 6033
SEMAPHORE_DB_DIALECT: mysql
SEMAPHORE_DB: ansible_ui
SEMAPHORE_PLAYBOOK_PATH: /tmp/semaphore/
SEMAPHORE_ADMIN_PASSWORD: /run/secrets/admin_password
SEMAPHORE_ADMIN_NAME: admin
SEMAPHORE_ADMIN_EMAIL: biuro@wojst.pl
SEMAPHORE_ADMIN: admin
SEMAPHORE_ACCESS_KEY_ENCRYPTION: changeme
SEMAPHORE_LDAP_ACTIVATED: 'no’
secrets:
– mysql_password
– admin_password
secrets:
mysql_password:
file: /sec/mysql_password.txt
admin_password:
file: /sec/admin_password.txt
Nie obyło się oczywiście bez problemów. Podczas doinstalowania docker-compose do działającego kontenera z Dockerem wywalało błąd:
process_linux.go:458: setting cgroup config for procHooks process caused: can’t load program: operation not permitted
Tutaj wykorzystałem główny atut Dockera – takie same kontenery można uruchomić na różnych maszynach. Po dłuższej walce z kontenerem LXC zaorałem go i uruchomiłem od nowa tym razem jako templatke wykorzystałem Debiana 12 (co rozwiązało wszelkie problemy). Wewnątrz utworzyłem kontener Dockerowy z phpmyadmin. Później doinstalowałem compose i utworzyłem instancje semaphore. W key store dodałem klucz wygenerowany w kontenerze LXC, który został skopiowany na wszystkie maszyny. Podczas dodawania inventory należy wskazać odpowiedni klucz.
Dodatkowo w VirtualBoxie na laptopie uruchomiłem dwie maszyny (jedna z Debianem, druga z RockyLinux). Na nich testowałem playbooki przed commitem do repo. W ten sposób na Semaphorze miałem gotowe, działające scenariusze.
Warto w tym miejscu wspomnieć, że wszystkie maszyny mają dzienny backup realizowany przez Proxmoxa. Oprócz tego posiadają protected backup w kluczowych momentach. Gwarantuje mi to powrót w razie awarii do pewnego miejsca w konfiguracji plus pewność, że Proxmox nie usunie tego pliku.
Zauważyłem, że każdy reboot Proxmoxa generuje problemy w nginx – nie ładuje vhostów na obu web serwerach. Wszystkie maszyny mają ustawioną opcję uruchamiania podczas bootowania. Jedną z dostępnych opcji były snippety Proxmoxowe – mogłem napisać skrypt, który uruchamia po kolei maszyny, odczekuje jakiś czas i uruchamia następną. Jako, iż w Linuxie daną rzecz można wykonać często na kilkanaście sposób wybrałem inne rozwiązanie. Zmodyfikowałem plik /etc/fstab, wewnątrz którego mam zdefiniowane montowanie udziałów NFS, aby wykonywał kilka prób połączenia na wypadek gdy serwer nginx wstanie szybciej niż nfsowy. Drugą modyfikacją jest prosty skrypt bashowy, który cron uruchamia podczas reboota – sleep 10; /usr/sbin/nginx – t && /usr/sbin/nginx -s reload. Na ten moment pomogło 🙂
Właśnie teraz sobie uświadomiłem, że w serwerze mam tylko jeden dysk 250 GB. Dlaczego nie dorzuciłem tam drugiego i zrobiłem z nich RAIDa? Bardzo dobre pytanie…
Przyszła pora na kolejny element labowej układanki – serwer Redis. Utworzyłem klon szablonu na bazie RockyLinux, a następnie zainstalowałem, skonfigurowałem i zabezpieczyłem samego Redisa. Będzie od dostępny dobrowolnie, każda strona będzie musiała go dodawać ręcznie. Do testów wykorzystam backup firmowej strony, który w moim labowym Intranecie znajduje się pod adresem wojst.pl.lcl. Zainstalowałem wtyczkę Redis Object Cache, a następnie skonfigurowałem ją.
Dodatkowo dorzuciłem serwer Redis do inventory Ansible Semaphore i uruchomiłem na nim wymagane playbooki.
Napisałem playbook tworzący środowisko WWW dla nowego usera. Playbook wymagał doinstalowania na serwerze bazodanowym pakietu python3-mysqlclient oraz pakietu python3-mysqldb na serwerze z proxysql. Na serwerze FTP wymagany jest pakiet python3-passlib, który pozwoli utworzyć hasło dla usera.
Playbook dostępny jest w repo challengu. Szybka analiza co robi po kolei:
– Kasuje plik /tmp/passwordfile, do którego zapisywane jest wygenerowane hasło podczas zakładania usera. Ansible Semaphore trzyma całą historię wykonanych tasków, więc bez problemu mogę tam podejrzeć hasła wygenerowane dla danego usera, jednakże w razie czego nie kasuję tego pliku na koniec, ale dopiero przy uruchomieniu następnego.
– Na głównym serwerze bazodanowym utworzenie bazy oraz usera i nadanie odpowiednich uprawnień dla niego. Przypisywany jest dostęp z całej podsieci. To właśnie w tym miejscu generowane jest hasło, które zostaje zrzucone do pliku. Robię to tyko na jednym, ponieważ włączona jest replikacja.
– Dodanie usera do proxysql i zapisanie listy userów.
– Utworzenie użytkownika ftp i odpowiednia jego konfiguracja.
– Na serwerze nfs następuje: utworzenie katalogu dla plików strony oraz utworzenie pliku konfiguracyjnego dla wirtualnego hosta nginx. Szablon wypełniany jest odpowiednimi zmiennymi i zrzucany do pliku domena.conf.
– Końcowy etap to reload nginxa na web serwerach.
Mam świadomość, że można w inny sposób to napisać, aby zmienna z userem była przechowywana w oddzielnym miejscu, ale mimo wszystko i tak trzeba robić commit przy nowym userze, więc bez różnicy czy zmienna jest w oddzielnym pliku czy w głównym yamlu.
Przedostatnim z etapów (które planuję na ten moment) jest wdrożenie monitoringu. Do tej pory nie miałem jeszcze okazji korzystać z Prometheusa połączonego z Grafaną, więc idealna sytuacja aby go poznać. W tym celu utworzyłem kolejną maszynę na bazie Debiana. Właśnie na nim zainstalowałem wspomniane oprogramowanie, a w kolejnym, ostatnim etapie laba dorzucę jeszcze do tej maszyny serwer syslogów. Jako manuale do instalacji posłużyły mi oficjalne dokumentacje.
O ile instalacja Grafany ograniczyła się do dodania repo, zainstalowania pakietu i wystartowania usługi tak w przypadku Prometheusa konieczne było pobranie odpowiedniej paczki i na jej podstawie utworzenie nowej usługi. Pomocny okazał się video tutorial, który oglądałem 74. dnia wyzwania #100DaysOfLinux. Co ciekawe Grafana po instalacji zużywała 100% CPU. Myślałem, że problemem jest tylko 1 core jaki przypisałem do maszyny. Zwiększyłem ilość do 3, uruchomiłem ponownie maszynę i zużycie spadło do wartości bliskich zeru.
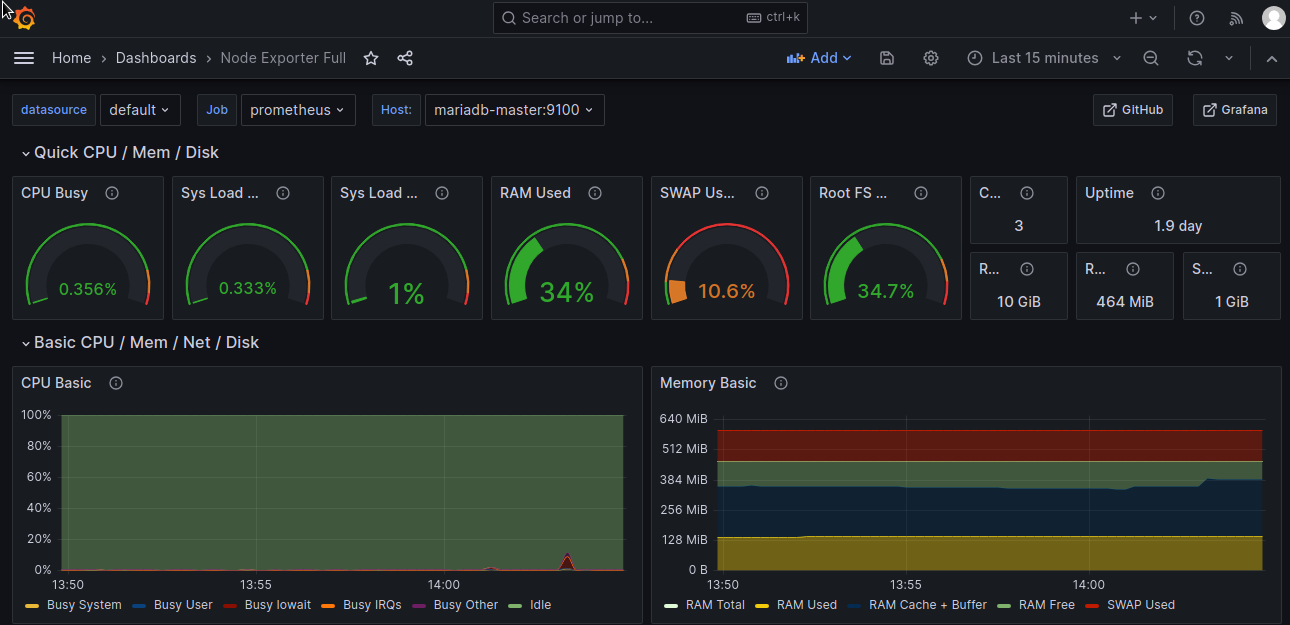
Do Prometheusa dodałem Node Exporter uruchomiony na serwerze monitoringu, a następnie w Grafanie zaimportowałem dashboard Node Exporter Full. To właśnie na nim będę sprawdzał statystyki serwerów. W międzyczasie utworzyłem playbook Ansible (na bazie innych dostępnych na GitHubie), który na serwerach instaluje Node Exporter. Następnie dodałem go do Semaphore i uruchomiłem – instalacja przebiegła prawie bezproblemowo. Na RockyLinux brakowało komendy tar. Dorzuciłem instalkę do playbooka, commit do gita i tym razem ukończyło pozytywnie zadanie. Pozostało jedynie dodanie targetów do Prometheusa, ale…
W tym momencie uświadomiłem sobie, że nie mam serwera DNS. W Prometheusie bym musiał dodawać targety po adresie IP, które później będą widoczne w Grafanie. Mało czytelne rozwiązanie. W związku z tym utworzyłem kontener Dockerowy z dnsmasq. W pliku konfiguracyjnym dopisałem mapowanie hostname na adresy IP maszyn wirtualnych. Modyfikowanie pliku konfiguracyjnego wykonuję przez panel WWW serwera dnsmasq.
Teraz w Grafanie wygląda to dużo lepiej:
Dodatkowo w Proxmoxie dorzuciłem do maszyn tagi dotyczące systemu operacyjnego. Dzięki nim w szybki sposób mogę zweryfikować jaka VM działa z jakim SO. Swoją drogą do serwera mam włożone tylko 5GB pamięci RAM. Trzeba dobrze kalkulować, aby ogarnęło wszystkie 14 VieMek 😀
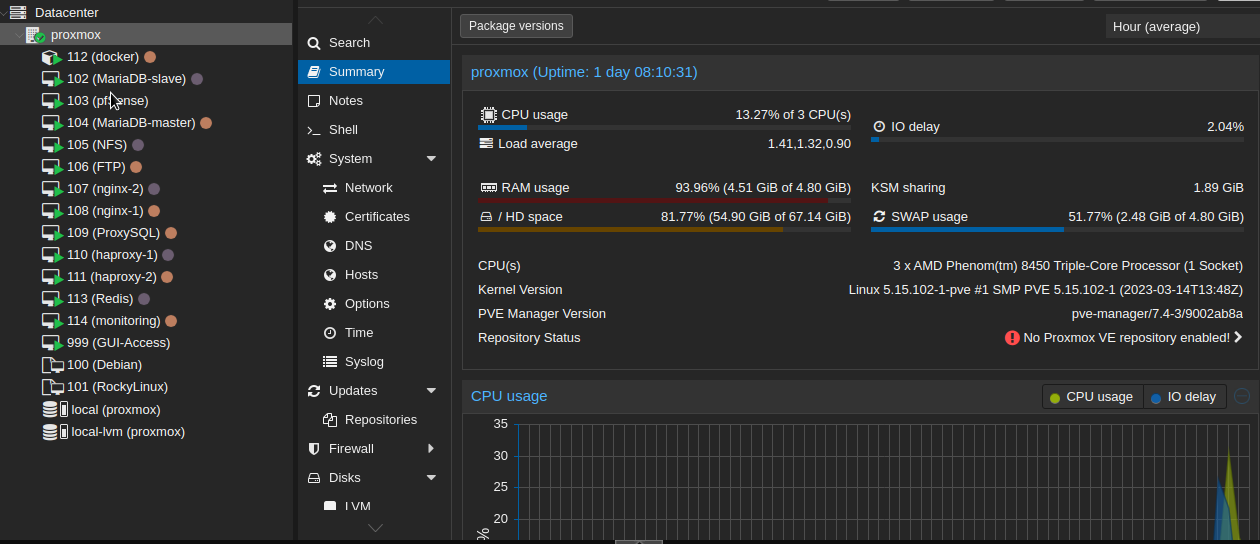
Na Proxmoxie włączyłem uwierzytelnianie dwuskładnikowe. Po przesiadce na NGROK serwer dostępny jest cały czas online, nie tylko w przypadku ustanawiania czasowej sesji. Dzięki temu stanowi to dodatkowe źródło zabezpieczeń samego Proxmoxa. Do generowania OTP wykorzystuję Google Authenticator.
Kolejnym etapem w rozbudowie projektu będzie wdrożenie serwera syslogów, który będzie zbierał logi ze wszystkich hostów. W tym przypadku kluczowe jest, aby czas ustawiony na maszynach był spójny. Wykorzystałem do tego protokół NTP. W kontenerze LXC na którym działa Docker odpaliłem kontener, który pełni rolę serwera NTP. Wykorzystałem obraz cturra/ntp. Następnie utworzyłem playbook Ansible, który wszystkie maszyny konfiguruje jako klientów NTP (w przypadku RockyLinux wykorzystałem chronyd, natomiast na Debianie usługę ntp). Następnie podpiąłem wspomniany playbook do Semaphore.
Wszystkie wykorzystane w tym projekcie playbooki znajdują się w repo challengu #100DaysOfLinux, które dostępne jest pod pod tym adresem: https://github.com/wojtex113/100daysoflinux/tree/master/ansible-playbooks
Przyszedł czas na ostatni etap – wdrożenie rsysloga. Na serwerze z monitoringiem zainstalowałem i skonfigurowałem rsysloga jako serwer. Skonfigurowałem go, aby obsługiwał zarówno protokół TCP jak i UDP. Docelowo jednak na klientach wykorzystam ten pierwszy. Następnie przystąpiłem do konfiguracji klientów. Jak się okazało na Debianach rsyslog był już zainstalowany. Pozostała jedynie modyfikacja pliku konfiguracyjnego. Jak wspominałem wcześniej (albo i nie) playbooki Ansible przygotowywałem na środowisku lokalnym (VirtualBox na laptopie, na nim wirtualka z Debianem i druga z Rockim) i gdy działały dopiero robiłem commit do repo i na końcu dodawałem go do Semaphore. Pierwsza próba uruchomienia playbooka zakończyła się niepowodzeniem. Okazało się, że problem był w lokalizacji pliku konfiguracyjnego na Debianach. Poprawka, commit, kolejny task zakończony sukcesem 🙂
Ansible UI, czyli Semaphore na ten moment prezentuje się następująco. Wszelkie errory to tymczasowe błędy na maszynach (przywieszony firewall itp, ograniczenia bare metala).
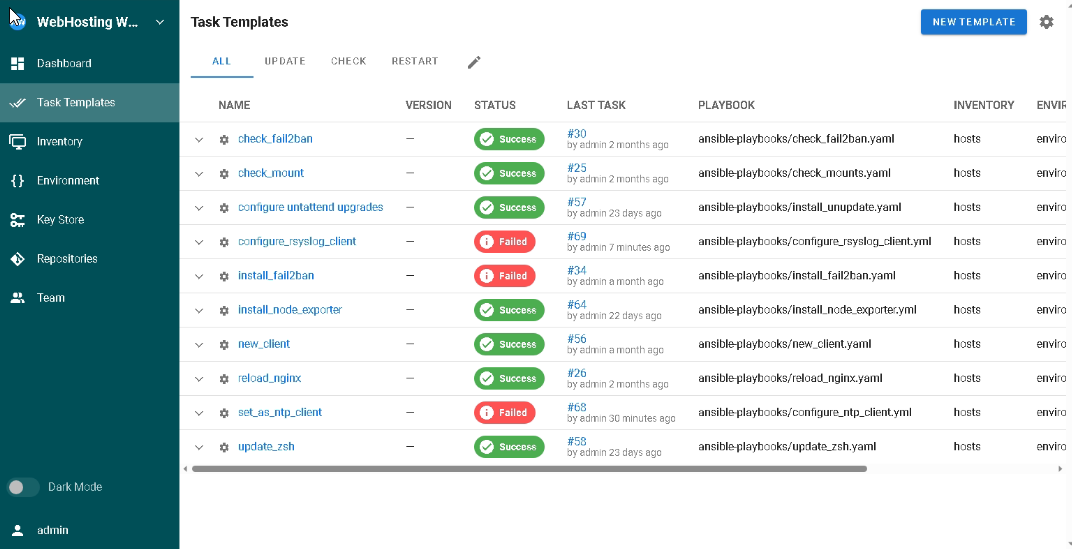
Główny zamysł projektu właśnie został osiągnięty 🙂 Udało mi się to w przeddzień ukończenia Challengu #100DaysOfLinux.
W kolejnych etapach powyższy projekt będę jeszcze modyfikował, udoskonalał, rozbudowywał. Wszelkie aktualności będę wrzucał do tego wpisu.